
Introduction
In today's digital-first world, the ability to tap into the real-time pulse of social media is a business superpower. Companies need to process a constant stream of unstructured content to track brand sentiment, measure campaign impact, and get ahead of emerging trends. The challenge isn't just getting the data; it's building a system that can handle the volume and velocity without breaking the bank or requiring a dedicated operations team.
This post details how to build a scalable, cost-efficient, and serverless data pipeline on AWS to ingest, process, and visualize social media data. This architecture is designed to turn chaotic social chatter into clear, actionable insights.
The Goal: Real-Time Social Media Intelligence
Our objective is to create a fully automated system that can:
- Track Brand Health: Instantly see what customers and critics are saying about your brand across platforms like Twitter, Facebook, and Reddit.
- Identify Emerging Trends: Detect spikes in conversations or popular hashtags to spot opportunities and mitigate potential crises early.
- Analyze Marketing Campaigns: Go beyond vanity metrics and measure the real-world conversation and sentiment driven by your marketing efforts.
- Monitor the Competition: Keep a close watch on your competitors' social media strategies and customer interactions.
- Enable Data-Driven Decisions: Replace guesswork with a live feed of market intelligence to guide your business strategy.
This pipeline is engineered to be hands-off, automatically scaling to handle massive data volumes cost-effectively.
Architecture Overview
The solution architecture is built using the following AWS components.
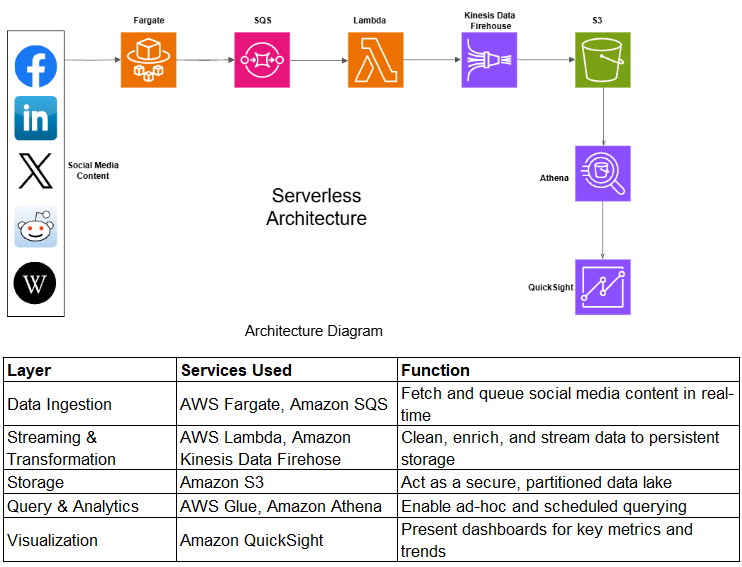
Building the Pipeline - Step by Step
Let's walk through how these services work together to bring our data pipeline to life.
1. Fetching Social Media Data
- Use social media APIs (e.g., Twitter, Instagram) with access tokens for continuous data collection.
- Implement retry logic and robust error handling in ingestion scripts.
- Containerize fetchers using Docker and deploy to AWS Fargate.
- Schedule fetcher tasks using Amazon EventBridge.
2. Buffering with Amazon SQS
- Use Amazon SQS as a decoupling mechanism between ingestion and processing.
- Configure dead-letter queues (DLQs) to capture and isolate failed messages.
- Enable server-side encryption (SSE) and monitor queue health using CloudWatch metrics like ApproximateNumberOfMessagesDelayed.
3. Data Processing and Streaming
- Use AWS Lambda to parse JSON responses, clean text, and extract entities (e.g., hashtags, mentions).
- Secure Lambda functions with least-privilege IAM roles.
- Deliver processed data to Amazon Kinesis Data Firehose for buffering and delivery.
- Enable logging and failure notifications in Firehose for troubleshooting.
4. Scalable Storage with Amazon S3
- Structure the data lake using logical prefixes for efficient partitioning:
- s3://social-data/twitter/year=2025/month=07/day=17/
- Enable versioning, encryption with AWS KMS, and apply lifecycle policies for archival and cost optimization.
5. Querying with Athena and Glue
- Catalog incoming data with AWS Glue, defining external tables with partitioning.
- Store data in columnar format (e.g., Apache Parquet) to reduce query costs.
- Use partition projection to speed up query performance.
-
Schedule recurring queries with EventBridge and export results to S3 for downstream consumption.
6. Visualization with Amazon QuickSight
Connect QuickSight to Athena datasets and configure periodic data refreshes.
-
Build interactive dashboards to visualize:
- Post volume trends
- Hashtag frequency
- Sentiment distribution
Implement row-level security to control access based on user roles.
Share dashboards via embedded links or scheduled email reports.
Deployment Steps
- Set Permissions & Queues: Create necessary IAM roles and SQS queues, including dead-letter queues for error handling.
- Deploy Ingestion Services: Launch the data fetcher on AWS Fargate, then configure AWS Lambda and Kinesis Firehose to process and deliver the data stream.
- Configure Storage & Catalog: Create an S3 bucket with lifecycle policies, then use AWS Glue to crawl the data and create a queryable catalog.
- Validate & Visualize: Test queries with Amazon Athena to ensure data integrity, then connect to Amazon QuickSight to build dashboards.
- Automate Everything: Use AWS CloudFormation or Terraform to automate this entire infrastructure for quick and reliable deployments.
Monitoring and Logging
A production-ready pipeline requires robust monitoring:
- AWS CloudWatch: Use CloudWatch Logs for all Lambda functions and Kinesis Data Firehose delivery streams. Set up CloudWatch Alarms to get notified about SQS queue depth increases, Lambda execution errors, or Firehose delivery failures.
- AWS X-Ray: For complex processing logic, use X-Ray to trace requests as they travel through Lambda and other services, making it easy to pinpoint bottlenecks.
Future Enhancements
This architecture is a powerful foundation, but it's also designed for extensibility. Here are a few ways to enhance it:
Sentiment Enrichment with Amazon Comprehend: Enhance analytics with sentiment detection, entity recognition, and key phrase extraction directly in Lambda using Amazon Comprehend.
Real-Time Alerts: Trigger anomaly alerts (e.g., spikes in negative sentiment) using Amazon SNS integrated with Slack, email, or incident response tools.
Advanced Analytics with Amazon Redshift: Migrate enriched datasets from S3 to Redshift using AWS Glue for advanced joins and historical trend analysis.
ML-Driven Insights: Integrate Amazon SageMaker to train and deploy models for:
- Influencer detection
- Topic clustering
- Fake news classification
These models can be invoked in real-time by the Lambda function during processing.
Conclusion
This serverless AWS pipeline delivers an efficient, scalable solution for ingesting and analyzing social media data in real time. By leveraging AWS managed services it minimizes operational complexity while enabling rich insights and proactive decision-making.
Whether you’re monitoring brand sentiment, assessing marketing impact, or exploring predictive analytics, this architecture offers a robust foundation that scales with your business needs—ready for future enhancements in AI, alerting, and advanced analytics.



Top comments (2)
Building a serverless social media ingestion pipeline on AWS is easier than it seems. Use Lambda, SQS, and S3 for scalability and cost efficiency. If you lack AWS expertise, you can hire developers to set up the architecture, automate tasks, and optimize analytics dashboards.
That’s a fair point, those core services cover most of the scalability needs and bringing in AWS expertise can certainly streamline the setup and optimization.